
In today’s high-performance computing (HPC) landscape, storage solutions that offer speed, scalability, and reliability are essential. Lustre, an open-source parallel file system, is a popular choice for HPC environments due to its capacity to handle large datasets and intensive workloads. When deploying Lustre on Oracle Cloud Infrastructure (OCI), achieving an optimized design that balances performance with cost-efficiency requires careful planning.
Let’s explore key Lustre infrastructure design patterns tailored for OCI, focusing on strategies to meet diverse storage needs and performance benchmarks. From selecting the right storage configurations to optimizing network setups and data access protocols, we’ll walk through best practices and design approaches that can help you build a robust Lustre environment on Oracle’s cloud platform.
The proposed solution is intended as an unmanaged infrastructure by Oracle. Once the infrastructure is created and deployed, its management will be entirely the responsibility of the end user. In this design, Oracle will only provide the IaaS resources.
In a Lustre file system, the key components are:
- Metadata Server (MDS), Metadata Target (MDT).
- The MDS handles metadata operations, such as file creation and directory structures, and stores this metadata on the MDT
- Object Storage Server (OSS), Object Storage Target (OST)
- The OSS manages actual file data, which is stored on one or more OSTs to enable efficient parallel access.
- Management Server (MGS), Management Target (MDT)
- The MGS provides centralized management, coordinating the configuration and status of the entire Lustre system.
Components ending in “T”—like MDT, MGT and OST—represent the physical disks or volumes where metadata and file data are written, making up the storage backbone of the system.
In the following images from the Lustre manual, we see diagrams of typical Lustre infrastructures.
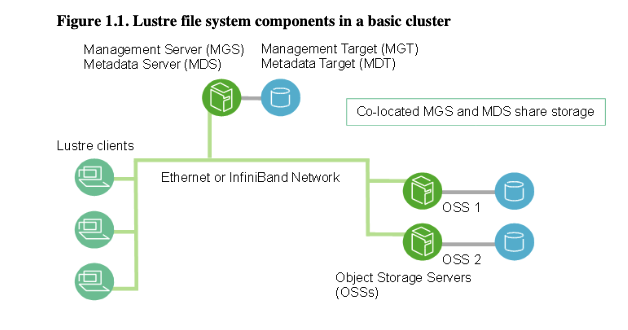
Physical resources can be managed in Active/Active or Active/Passive clusters using various types of technologies that are not included in the Lustre application but can be implemented in the underlying Linux operating systems.
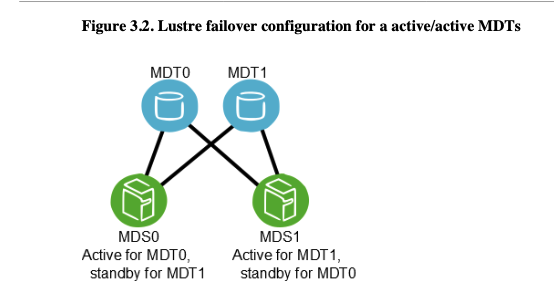
Lustre best practice Architecture Design
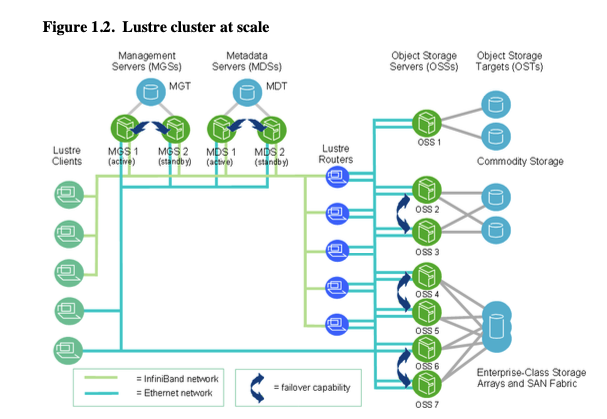
In the following image, we begin to see a more structured and complex installation of Lustre. Indeed, we can see the introduction and use of failover clusters across the various components of the infrastructure, namely the MGS, MDS, and OSS servers.
Of course, the network plays a fundamental role in this type of infrastructure. The machines must be able to communicate with each other over a dedicated network, separate from the one used by the clients accessing the file system. While this segmentation is not mandatory for operation, it is highly recommended to avoid bottlenecks and network data saturation.
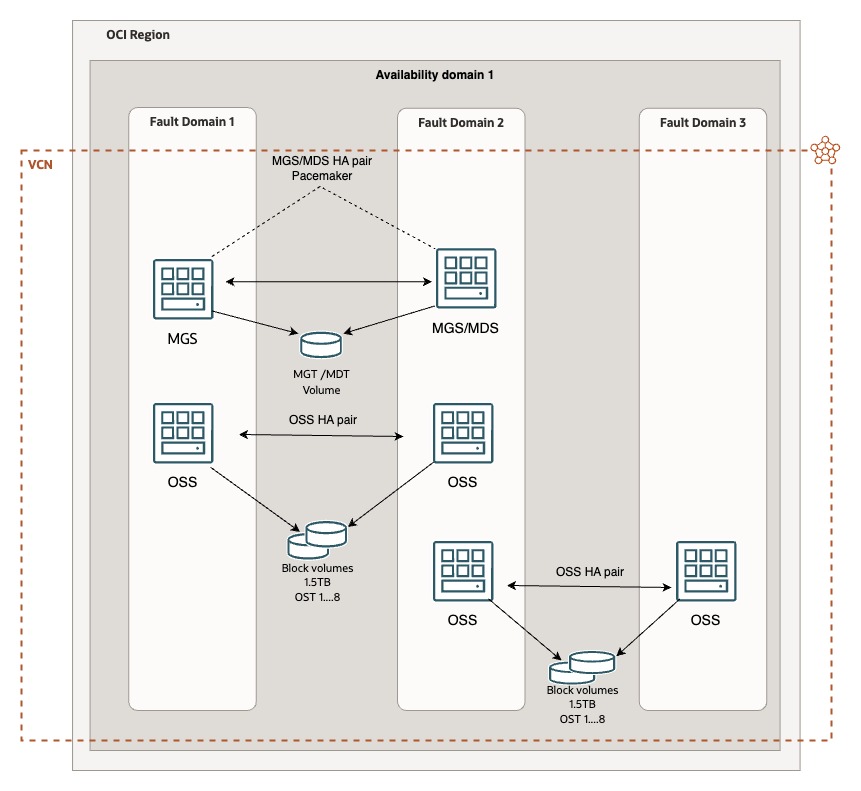
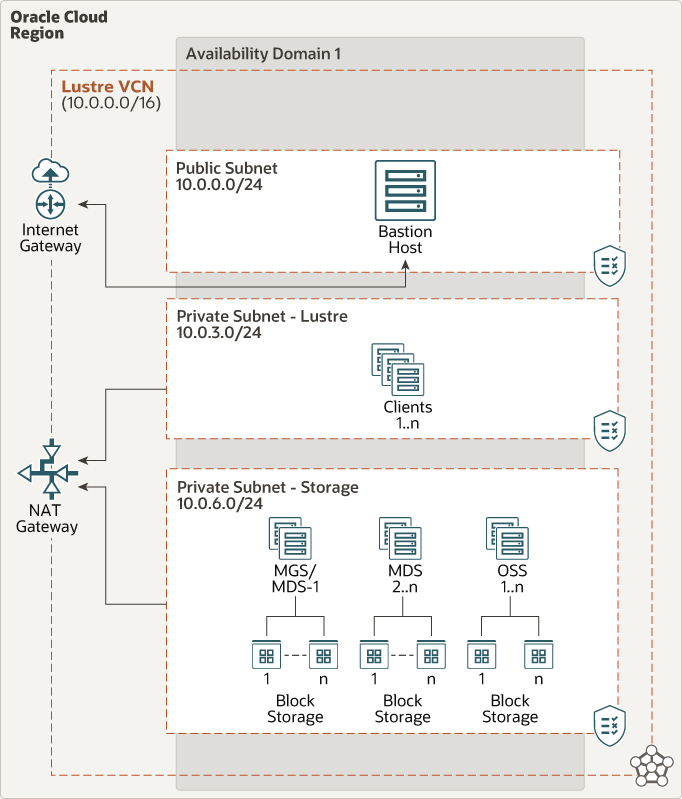
Therefore, we can translate the infrastructure suggested by the Lustre manual, optimizing it for Oracle OCI infrastructure as outlined below. The failover clusters shown in the diagram are not mandatory for the operation of the infrastructure, but they are recommended because, if a volume within the Lustre file system becomes unreachable for any reason, the entire file system will be compromised, resulting in potential data loss. Thus, it is important to evaluate whether the data used for processing and served to the HPC cluster needs to be persistent or if it does not serve a critical long-term function.
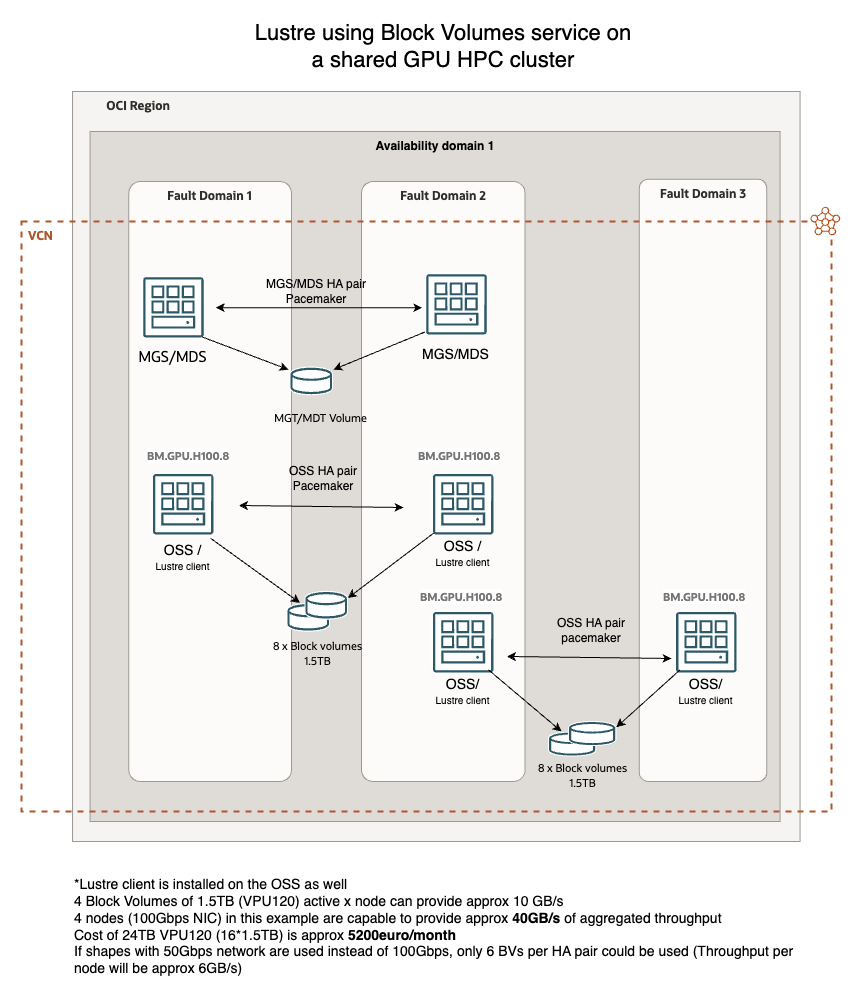
It is important to remember that block volumes with VPU120 (those with the highest performance) are available only when using compute shapes with at least 16 OCPUs, and to achieve maximum performance (2.6 GB/s), they must have a size of at least 1.5TB each. Therefore, it is necessary to calculate the network allocated and provided by the compute shapes to determine how many block volumes to connect to each machine in order to avoid potential bottlenecks and to take full advantage of the available throughput for each node, considering both the network bandwidth and the throughput of the connected volumes.
A Lustre cluster using Block volumes across multiple OSTs might achieve an aggregate throughput of hundreds of GB/s, depending on the number of nodes and network configuration. While BVs are slower than NVMe, this setup still provides a tremendous aggregate throughput, substantially a lot of more than our FSS service, as it combines the read/write speeds of all nodes, providing as well business continuity. It is definitely the best practice infrastructure design to follow when deploy the Lustre architecture.
Compute shapes and network
Seeing that the network plays a fundamental role in the throughput provided by Lustre, choosing the right shape in OCI is crucial. To take advantage of the throughput offered by Block Volumes, it is essential to select a shape that provides enough network bandwidth so that it does not become a bottleneck for the performance offered by the BVs. Therefore, making a quick calculation, if the goal is to achieve at least 5GB/s per node, one would need at least 40Gbps of network bandwidth and, of course, an adequate number of block volumes with appropriate VPU performance to deliver such throughput.
In this case, Optimized compute shapes are probably the best choice for cost/performance, but given the cost of the HPC cluster that will likely utilize the Lustre architecture, a Bare Metal cluster will undoubtedly be the most suitable solution to ensure both computational power and high-performance networking. Therefore, we can use VMs for POC environments or for organizations with limited budgets that occasionally need to use this type of architecture, allowing them to activate it on-demand and thus achieve significant cost savings.
Lustre on Oracle Marketplace
In another image taken from the Oracle OCI Marketplace Oracle OCI, we can see the subnet-level distribution of the Lustre service. In fact, it is possible to deploy the infrastructure directly using a preconfigured Terraform script from the marketplace just with ‘one click’.
As can be seen, Lustre has a dedicated subnet to better manage access security from the other subnets where the clients accessing the file system are located.
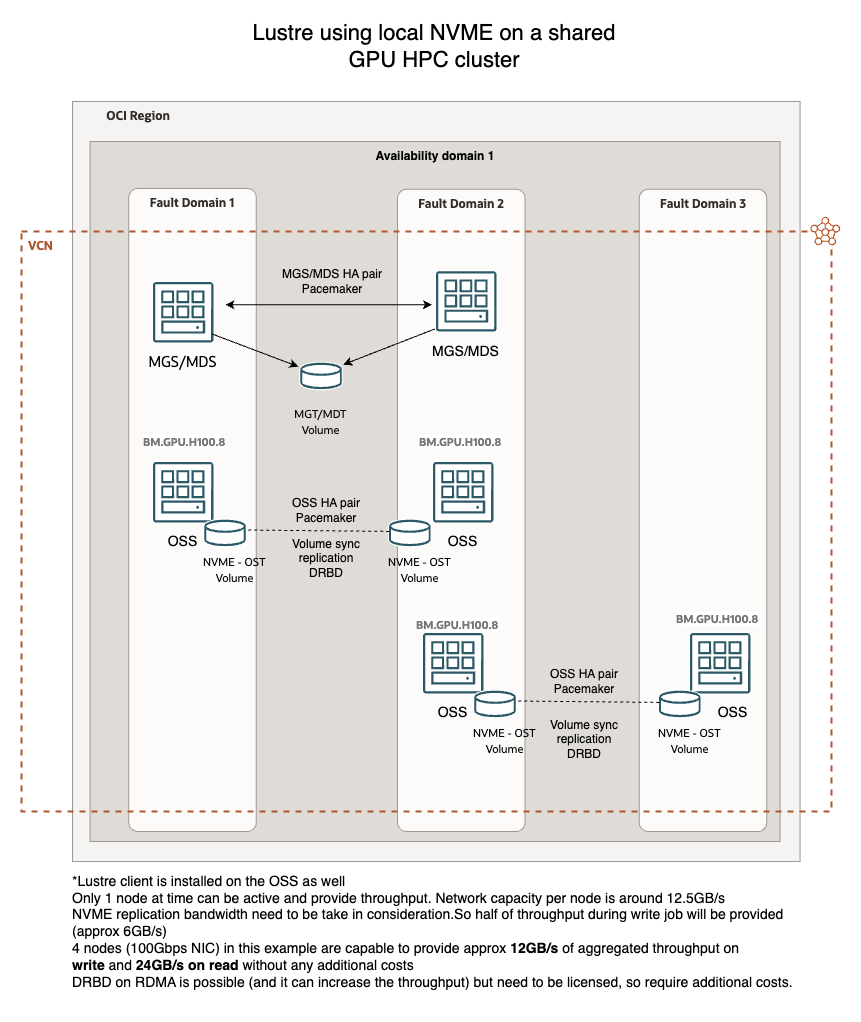
Another type of approach for cost savings on GPU HPC cluster.
These infrastructure diagrams are not the only possibilities with Lustre. In fact, when trying to optimize costs for deploying and using HPC clusters along with storage, one can consider using the hosts used for HPC to also provide storage services with Lustre, using the same locally connected NVMe volumes provided by the Bare Metal shapes. This can lead to significant cost savings on the infrastructure. However, it is important to note that Lustre can utilize more than half of the CPU under stress to ensure throughput, so it is advisable to use this type of deployment only if the HPC cluster predominantly processes data using GPUs rather than CPUs. Additionally, if the data being used must be persistent and is of fundamental importance, it is essential to implement data replication between hosts to avoid potential system downtime, as the disks are connected locally and cannot be attached at the same time between hosts. The calculation of the bandwidth required for replication is crucial to avoid service disruptions. Obviously, if RDMA on a separate network is not considered, the performance delivered by a single node is halved, as are the overall performance levels of the cluster. For this reason, in infrastructures where very expensive shapes are used for HPC, I don’t see the use of local NVMe resources as practical at all costs. Instead, I suggest investing a few thousand euros more per month to achieve significant performance levels. Approximately 20GB/s in aggregate throughput can be achieved by using about 18TB spread across 12 block volumes divided among 4 nodes (6 shared attached BVs per node pair).
Node redundancy and replication are essential to prevent issues. Since the NVMe disks are local, if a cluster node encounters problems, the entire Lustre filesystem could be affected. This solution should definitely not be considered a best practice but may be considered when there is a need to reduce costs across the infrastructure and to reallocate valuable resources in terms of budget and throughput that would otherwise remain unused. Therefore, nodes should be replicated in pairs to prevent service and data loss, and NVMe disk replication should be planned to address potential failures in any of the nodes.
Conclusion
Designing an effective Lustre infrastructure on Oracle OCI involves careful consideration of various components, alongside the critical role of networking. The use of dedicated subnets enhances access security, while failover clusters provide additional resilience to the system, protecting against potential data loss. By optimizing the deployment to leverage existing HPC hosts for storage services, significant cost savings can be achieved. However, it is essential to assess the workload characteristics and ensure that data persistence is maintained through effective replication strategies. Ultimately, the right balance between performance, cost, and reliability will enable organizations to harness the full potential of Lustre in high-performance computing environments.
Resources:
- Lustre Manual
- Marketplace Oracle OCI
- Oracle OCI infrastructure
- Lustre official website
- Download Lustre
At the time of publishing this post, I am an Oracle employee, but he views expressed on this blog are my own and do not necessarily reflect the views of Oracle.

Pingback: Understanding Lustre Performance: Throughput in High-Demand Scenarios – Marco Santucci